|
本网导读1:DNA编码是人类遗传信息的唯一载体 |
|
现代生命科学研究发现,人类细胞中的DNA编码,是存储生命遗传信息的唯一载体。 “DNA”这个代号,已经是耳熟能详、却又充满秘密的词汇。虽然它就存在于我们的体内,但是,对于很多人来说,DNA依然是一个抽象的名词。它究竟是什么样子?我们如何能看见它呢?为什么它能承载着生命的遗传信息?它和人类的起源有什么样的关系?等等疑问,很少人能够回答。希望从下面的介绍并结合本网第二节的内容,帮助您对DNA有一个初步的了解,并知道是如何从DNA上,看到了人类的起源。 一.生命遗传信息的发现 1. 发现生命遗传信息的历史: 在很久以前,人类已经认识到生命中的信息是来自父母遗传。然而,当显微镜的放大倍数达不到200倍时,就无法看到精子——这来自父亲的唯一生命信息载体。 1677年,荷兰显微镜制作家列文虎克(Antonie van Leeuwenhoek)用他制作的300倍显微镜,首次观察到了精子。由此知道,父亲的贡献不再是单纯的液体,而是液体中无数“小蝌蚪”样子的精子。从此,开创了认识父系遗传信息载体的历史。随着显微镜放大倍数越来越高,人们看到在大多数情况下,只有一个精子与母亲的卵子结合,形成了新的生命。 上世纪50年代,高倍显微镜让人们看到了,人类细胞核中包含23对(46条)染色体,其中23条染色体来自父亲,23条染色体来自母亲。还发现了卵子中的线粒体,进一步知道生命遗传信息,完全承载于染色体和线粒体之中。 真正认识遗传信息的实质,是借助高倍显微镜和X射线衍射照片,发现在每一个染色体中,包含着一个双螺旋结构的分子。这个长长的犹如旋转楼梯形状的DNA分子,可以简化为一条A、T、C、G,四个碱基字符表达的DNA编码序列。线粒体的遗传信息,则是16,569个DNA碱基字符表达的环状DNA编码序列。(参看本网第二节) 结论:46条染色体的DNA编码序列,以及线粒体的环状DNA编码序列,承载着全部的生命遗传信息。而全世界人与人之间DNA编码序列的差异,仅仅只有千分之一。 2.生命遗传信息的传递 新生命的开始是源自一个卵子受精的过程。上亿的精子,真正达到卵子周围的,仅仅只有上千个。而最后进入卵子的,通常只有一个精子。 男人每一个精子中,都包含有22条常染色体和一条性染色体(Y染色体或X染色体)。包含Y染色体的精子,将决定受精卵是男孩的胚胎;包含X染色体的精子,将决定受精卵是女孩的胚胎。这两种精子各占总数的一半。精子中的Y染色体来自男人的父亲,X染色体来自男人的母亲;精子中的常染色体,是由那位男人的父母双方(未来胎儿的祖父、母)的常染色体,通过“减数分裂”的“联会”过程形成(参看第六节 DNA 解码的钥匙:P公式)。联会后的常染色体,包含着未来胎儿祖父、母的遗传信息。每一个精原细胞通过联会产生4个不同的精子,几千万的精原细胞通过各自的联会过程,产生上亿个精子,而每一个精子都是独一无二的。然而它们的DNA编码差异,却都远远小于千分之一。 精子是一个个会“激流勇进”的小“蝌蚪”。每一个“蝌蚪”的头部,都存储着23条染色体的DNA编码序列,其编码总数有30亿左右的字符。这些有序的编码序列,承载着父系的全部遗传信息,包含“物质的遗传信息”和“非物质的遗传信息”。小“蝌蚪”的头部是那么小,在长、宽、高都只有3微米左右的空间内,却存储了30亿的编码,以及其它一些组建DNA编码结构的物质。这样的存储密度,即使在现代电脑存储器的领域,也是难以达到的。(参看第9节第1页的内容) 卵子之中,同样包含有23条染色体,只是性染色体仅仅是X染色体。和精子的形成过程类似,卵子减数分裂的联会过程,使联会后的染色体,包含了未来胎儿外祖父和外祖母的遗传信息。卵子受精后形成的胚胎,就得到了来自父系和母系双方的全部遗传信息。 二.两个类型的生命遗传信息 生命遗传信息有两个方面的内容:“物质的遗传信息”(The
physical information)和“非物质的遗传信息” (The intangible information)。 1.染色体中“物质的遗传信息” DNA中绝大多数的遗传信息都包含在染色体中。每一条染色体都包含了一个DNA分子,这个分子可以看成是一长串的DNA编码序列。最长的人类染色体,是1号常染色体,它是由249,250,621个DNA编码组成。最短的是Y染色体,它由59,373,566个DNA编码组成(参看第七节 染色体数目的差异是猿进化成人的鸿沟)。 DNA编码包含的信息,表达在每一条染色体的DNA编码序列的字符编织顺序上。这一点不太好理解,我们还是用DVD上的电影来说明。承载着一部电影的一片DVD光碟,其信息完全是二近制的编码0和1组成,几十亿的0和1的字符编码,按照一定的序列编织,就存储了一部有声有形的电影。与此类似,染色体上A、T、C、G的4态编码,按照特定的顺序,就会编织出人身体的各个特征。例如,这一段编码确定了皮肤的颜色,另一段编码确定了鼻子的高低等等。 从20几万年前的科学亚当、科学夏娃的染色体编码序列起,经历上万代的遗传,代代都是非常严格进行复制的。我们和他们DNA编码的差异仅仅是千分之0.5。因此,他们非洲的子孙和欧洲、亚洲的子孙,DNA编码的差异才会是千分之一(参看本网第2节,第3小节“ 谁是线粒体夏娃的夫君?”)。 2006年美国国立人类基因组研究所(National
Human Genome Research Institute-NHGRI)发布的报告说:“在2003年4月,当研究人员完成了人类基因组计划的最后分析,他们确认,人类基因组的三十亿个碱基对的遗传字母,在每个人身上都是99.9%的相同。这也意味着在这个星球上个人的DNA差异,平均只有0.1%(千分之一)。” 也正因为如此,全世界人的外形和生理才那么一致,可以彼此输血、通婚和繁衍后代。 染色体的DNA编码序列,包含着被称为基因的序列,也包含着更多的非基因序列。全部的这些序列,都承载着生命的“物质的遗传信息”。当第一个受精卵形成后,一个新的生命就诞生了。现在的知识范畴内,认为是细胞中的三万多个基因,决定了人的生理、体型和外貌。但是,还不能确定非基因序列所产生的影响。 一个受精卵细胞核内,来自父亲的23条染色体和来自母亲的23条染色体并存着,而这两组染色体却不互相结合。以后身体各部位,增殖出来的千千万万细胞核中,染色体的DNA都是一样的。直到产生精子和卵子时,父方和母方的染色体才会发生“联会”,将他们各自的遗传信息加以融合后,再向下一代传递。 受精卵从一个开始,进行有丝分裂,一个变两个,两个变4个,4个变8个等等。开始的这些细胞完全是一样地被复制出来。奇妙的是,进入“分化”阶段以后,细胞核DNA仍然是一样的,细胞质却变成各式各样的,形成了人身体中各个不同部位的细胞。
图1 细胞核中的46条染色体 从图1中可以看到,来自父方和母方的各23条染色体,是呈“杂乱无章”的分布着。然而,它们却像管理细胞生长的两个团队,每队有23个指挥员,极其有序的、共同地指挥着细胞的分裂、分化,使一个单一的胚胎细胞长为一个成人。而23对染色体也被复制到全身的40到60万亿个(不同体重的人,有不同数量的细胞)细胞中去。 染色体中DNA编码,在人体生长过程中,表达出的编码信息会对细胞的生长产生影响。DNA编码信息通过转录和RNA(Ribonucleic acid—核糖核酸)的翻译,指导合成了人体各部位特定的蛋白质,构成了人体的各个部分。新的他(或她)这个实体,是父、母双方“物质的遗传信息”的成果。同时,这个实体也包含着父、母双方的 “非物质的遗传信息”,使这个“实体”成为一个有灵性的活人。 让我们看一个基因的DNA片段,使您了解什么是DNA编码:男人Y染色体的ZFY基因729个DNA编码序列(参看本网附:基因银行的DNA编码资料)。 1 gtgagttccacaggggtgttatgatggagttttagctagtaggccacatgtatttttatg 61 tgttgaatttgaaagaaaaaatttcaaaattcagtgatattcatgaatggttttcttgga 121 taagaagaaacagttgtgcatcaaccattcaggaaaaagaattaaaatcctctggtgatt 181 ttagtgaaaaggaaaataaatttctaaaatgttacctaactttaagtgaacgaaattaca 241 tggatctacttatactagcataaagcaggtataatttaccgagaagtggaagaagtacct 301 aggttatttgtaggactgattactatcctatgttgttttgaatgctgctttgcatattaa 361 aatttatttataggtgcagttaagctttactgtttgcatatatttggcttggagtcagtc 421 accaaagcagaaatgctggacttgatttttatgagttatttgctacacatttctaaattc 481 atgttcttttgtcactgcttgattgattttttttttttaactggagggggtgagattggt 541 tcatacttaaccaaaccagttctctcgattaggacattattataactcttaacattgaaa 601 agcagtaaaaggaatgttaataatttaaaagtatttgcccactaatgttcagaacacaag 661 ctttaaaaaattcatgaggagaccagaagtttgattaagcactcatactgctttcttttc 721 ctttcttag 分子人类学就是基于这些编码,去寻找人类的起源、繁衍和迁徙的历史。DNA编码病理学的意义,则不是这个学科的研究范围。 2.染色体中“非物质的遗传信息”(The intangible information) 每一个孩子从父母那里,不仅得到了身体,也获得了不能从肉体上看见的“非物质的遗传信息”。无论你对一个黑猩猩进行如何的教育和培养,你绝不可能使它达到小学生的听、说、读、写能力,取得小学的毕业文凭。这对于普通的人来说,是轻而易举的事情。这是为什么?因为人和黑猩猩除了在“物质的遗传信息”上有截然不同外,人还从父母那里得到了黑猩猩不具备的“非物质的遗传信息”。人类具有任何动物无法比拟的智慧,这些智慧虽然绝大多数来自于成长后的学习,但是学习和取得这些智慧的“能力”,绝对是在胚胎时期就已经具备了。 对于“非物质的遗传信息”,目前还讨论得很少。但是,只要承认我们也从父母那里,继承了在肉体上看不见的一些“能力”,那些能力就是来自“非物质的遗传信息”。这些信息不包含知识,却包含着学习知识的“能力”。小孩很自然听懂了妈妈的语言,学会了说话。逐步学会了读和写,进而也能表现出从父母那里继承的艺术、运动或其它才能。这一切都必须归结于对父母“非物质的遗传信息”的继承。 既然“人类细胞中的DNA编码,是存储生命遗传信息唯一的载体”,那么“非物质的遗传信息”,也必然承载于DNA编码之上。可能在非常久远的时间内,我们都不可能在DNA编码上,识别出哪些编码是承载这些信息的DNA编码片段,但是,它们的的确确存在于我们的DNA编码之中。 正因为如此,我们同样可以用DNA编码差异的比较,来判定人类“非物质的遗传信息”的差异。正如美国基因组研究首席专家文特尔(Dr.
John Craig Venter)所说的那样:“我们全都分享着百分之99.99相同的遗传密码,并不存在我们的种族区别”,“种族只是一个社会的概念,而不是一个科学事实。”。 不同种族的“非物质的遗传信息”差异也只会有千分之一、甚至万分之一的差异。人类学习听说读写的能力和喜怒哀乐的情感,是不会因为种族的差异而区别。一个边远之地的小孩,只要认真培养,也会成为一个优秀的大学生。 从人类发展和繁衍的历史长河来看,DNA编码的差别是十分微小的。25万年前的科学亚当、科学夏娃和我们的DNA编码差异只有千分之0.5(见第2节第3部分 谁是线粒体夏娃的夫君?),比现代人族群之间差别的千分之一更小。因此,他们和我们的非物质遗传信息,同样比现代族群之间的差别更小。这就是为什么科学夏娃比希拉里更像米歇尔,不仅仅是形体的相似,也应该是“非物质遗传信息”的相似。 我们可以依据对DNA编码的一些结论,推断出有关人类“非物质遗传信息”的几个结论: (1)不同个人之间的“非物质的遗传信息”差异是非常小的,并不存在优劣之分。
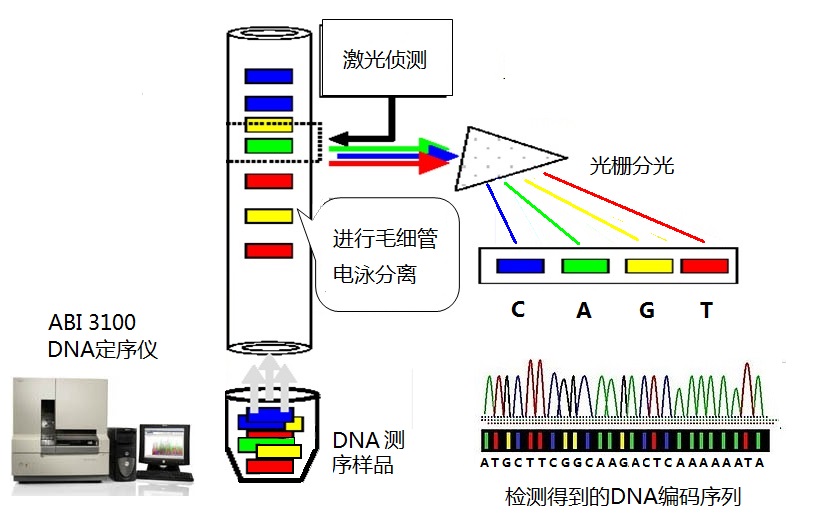
(2)在“非物质的遗传信息”上,人类共同祖先—科学亚当和科学夏娃,与非洲或欧亚族群现代人的差异,比非洲现代人和欧亚现代人之间的差异更小;或者说科学亚当和科学夏娃有着和我们同样的“非物质的遗传信息”。 (3)从人类DNA编码上看不到物质遗传信息的进化,人类在非物质遗传信息上,也同样不会有进化。 (4)人类与黑猩猩在DNA编码上有巨大的差异,同样在非物质遗传信息上,也有着巨大的差异。 (5)“非物质的遗传信息”差异,是人类和动物之间不可跨越的又一个鸿沟。 DNA编码也是“非物质的遗传信息”的必然载体,是我们在这里第一次提出。 三.怎样得到DNA编码序列 这里简单介绍一下DNA编码序列的检测方法,让我们知道DNA编码的序列是怎样得到的。 DNA 的检序方法很多,常用的方法是基于光谱分析的荧光法(fluorescence
based DNA sequencing)。将4种“荧光颜色标试剂”(fluorescently
labeled ddNTPs)加入到DNA样本中,每一种DNA碱基(A、T、C、G)将会对应一种颜色。在激光照射下,根据发出的颜色,就可以确定出检测到的DNA碱基码的类型,由此,得到一个片段的DNA编码序列。 图2
DNA编码序列的测定 人体的DNA样本可以从血液、口腔粘膜、毛发和体液等生物材料取得。经过裂解细胞、分离、提取DNA和DNA纯化等步骤,得到符合要求的DNA样品。使用生物学分子工程技术,将DNA样品切割为许多小的DNA编码片段,加入“荧光颜色标试剂”,再放入电泳缓冲液中。然后,置于DNA定序仪内,进行毛细管电泳分离。通过激光照射和光栅分光,捡测得到DNA碱基信号和小片段的DNA编码序列。再将各个小片段,通过端部DNA编码的搭接,组合成大段的DNA编码序列。于是,我们身体中的密码,就呈现在了眼前。它可以作为亲子鉴定、追查罪犯的依据,也可以用作人类起源、繁衍和迁徙的追踪。 四.从DNA编码上能看到些什么 1. 基因DNA编码中的档案库—GenBank 美国基因銀行(GenBank)是一个开放的序列数据库,它对所有公开可利用的核苷酸序列及其翻译的蛋白质进行收集、审查和注释。基因銀行由美国国家生物技术信息中心National Center for Biotechnology Information(NCBI)主管,是美国国立卫生研究院的下属机构。 该数据库建立三十多年来,已经成为最重要也是最有影响力的生物领域数据库,其数据正被全球数以百万计的研究人员免费获取与引用。 基因银行从世界各地的实验室,收集到超过10万多个生物物种的DNA和RNA样本,其数据量正以每18个月翻一番的速度持续指數增長。在2013年2月公布的版本中,该數據庫包含有1.62億個序列,含有1500億個核苷酸碱基(DNA 和 RNA编码)。这些数据,是成千上万科技人员的研究成果,也是数以亿计金钱换来的现代生物学和分子人类学研究的坚实基础。 本网所依据的DNA编码全部是来自该数据库,并提供了各编码信息在基因银行数据库的网址,读者可以进行查阅和对照。 2.不同学科对DNA编码不同的关注 和DNA编码紧密联系的现代科学,主要有分子生物学、分子医学和分子人类学。 分子生物学是以基因为对象,解释生命现象、疾病现象和生物学规律的学科。而分子医学则是用分子生物学理论和技术去认识、研究和诊治疾病的学科。这两个学科主要关注的是“构成基因的DNA编码”。目前发现的两万多个基因DNA编码总量,仅仅只占人类基因组总数31亿DNA编码的3%左右。 而分子人类学是人类学的分支,利用人类基因组的DNA遗传标记信息,去分析人类起源、民族繁衍和迁徙等多方面的问题,是一门DNA遗传标记分析和人类学交叉的学科。研究方法是比较DNA序列,寻找出DNA中包含的原始序列标记,以及不同族群的特定突变DNA标记。根据这些序列和标记的继承关系,寻找人类的起源、判断不同族群的亲属关系,寻找他们的发源地和迁徙路线。分子人类学关注的是人类基因组全部的31亿DNA编码。 (1)线粒体上的突变标记和疾病 人类线粒体DNA编码是一个环状的序列,它有16569个碱基编码,其中包含着
37个基因的编码。全世界人线粒体DNA编码序列是高度一致的,由于在人类繁衍中DNA的突变,不同族群的线粒体DNA编码,大约有百分之一的差异。1981年,剑桥大学的医学专家们首次测定了一个欧洲人的线粒体DNA编码序列——剑桥序列,这个序列一直是世界各国医学上重要的参考标准(见本网第2节)。 医学研究已经证明,线粒体DNA突变会产生一些疾病,而且还会通过母系遗传给下一代。目前,已经明确了在一些位置上的线粒体DNA突变产生的疾病,如在第8993位点T突变为G(T8993G),改变了涵括该点基因的性质,产生“视网膜色素变性”的疾病;G11778A突变,会发生“遗传性视神经病”;A3243G突变,导致“线粒体脑疾病”;T7445G突变,会导致听力丧失疾病等。这些都是分子医学关注的内容。 和分子医学不同,分子人类学首先关注的是:为什么全世界人线粒体DNA编码序列那么高度一致?为什么在至少16400多个位点上,不但碱基字符是相同的,连位置的编号也是相同的?那么,唯一的理由是全世界人出自一个母亲(线粒体DNA是由母系传承的),由此,诞生了“夏娃理论”。 而后,比较了非洲大陆内外,不同族群的线粒体DNA差异,发现非洲之外所有族群,在三个位点上,线粒体DNA发生了突变:A769G(第769位点上的A变成了G)、A1018G、C16311T。这就是分子人类学上有名的“L3线粒体DNA标记”,它表明非洲以外全部的人,都是一位女人的子孙,在这三个位点上,DNA碱基分别是G、G、T。而非洲人在这三个位点上,绝大多数是A、A、C(以上见本网第二节)。 全世界人都是一位女人的子孙,非洲以外全部的人,都是一位女人的后裔,这些来自DNA编码的结论,是进化论无法解释、也无法接受的。 (2)基因DNA编码的多态性(SNP) 分子医学还处于一个非常早期的阶段。美国国立癌症研究所的Judith E. Karp MD.和Samuel Broder MD.这样描述分子医学的任务: 发现决定细胞正常行为的基本分子;分析那些基因异常表达以及与疾病发生的关系;通过检查和纠正畸变的基因,对疾病进行诊断、治疗和预防[英文原文见注释
1]。 简而言之,分子医学就是从基因DNA编码上去寻找病因,同时从改变、纠正基因DNA编码的方向上,去寻找某些疾病治疗和预防的方法。在这里,识别出基因的DNA编码序列,发现不同人群和个体在基因DNA编码上的差异,就成为了最基本的工作。这个工作就是对基因SNP的研究。 什么是SNP?研究发现,基因DNA编码具有多态性(Single
Nucleotide Polymorphism)。这就是,不同人的基因DNA编码,在某些位点上,会有差异。例如,在一个人身上DNA编码是C,同一位点上,另一个人的身上却是G。 下面是从本网附录“基因银行的DNA编码资料”中摘录出的一个实例,可以看到这种差异:这是从人的6号常染色体上,取得的ATXN1基因DNA编码序列。这两个样本是取自不同的人,由不同研究人员在不同时期提供给GenBank的。 样本2:VERSION S64648.1 PRI 13-OCT-1993 (1-序列起始位点编号)变化:两个突变形成的缺失,两个突变形成的差异
gatccccccaaccgccaaccccgtcaccagtgcagtggcctcgg-cgcaggggccaccac tccatcccagcgctcccagctggaggcctattccactctgctggccaacatgggcagtct gagccagacgccgggacacaaggctgagcagcagcagcagcagcagcagcagcagcagca gcagcatcagcatcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagca gctcagcagggctccggggctcatcaccccgggtcccccccaccagccc-agcagaacca gtacgtccacatttccagttctccgcagaacaccggccgcaccgcctctcctccggccat ccccgtccacctccacccccaccagacgatgatcccacacacgctcaccctggggccccc ctcccaggtcgtcatgcaatacgccgactccggcagccactttgtccctcgggaggccac caagaaagccgagagcagccggctgcag(506-end) 样本4:VERSION X79204.1 PRI 07-OCT-2008 1375-序(列起始位点编号) 变化:没有变化(假定是原生码) gatccccccaaccgccaaccccgtcaccagtgcagtggcctcggccgcaggggccaccac tccatcccagcgctcccagctggaggcctattccactctgctggccaacatgggcagtct gagccagacgccgggacacaaggctgagcagcagcagcagcagcagcagcagcagcagca gcagcatcagcatcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagca cctcagcagggctccggggctcatcaccccggggtcccccccaccagcccagcagaacca gtacgtccacatttccagttctccgcagaacaccggccgcaccgcctctcctccggccat ccccgtccacctccacccccaccagacgatgatcccacacacgctcaccctggggccccc ctcccaggtcgtcatgcaatacgccgactccggcagccactttgtccctcgggaggccac caagaaagctgagagcagccggctgcag(1882-end) 对比4号样本,2号样本有两个位点的DNA字符缺失,缺失也是多态性(SNP)。另两个差异是:样本第5行第一个DNA编码字符,2号样本是g,而4号样本是c;最后一行第10个DNA编码字符,2号样本是c,而4号样本是t。同样的基因,在这4个位点上,就表现出了多态性(SNP)。那么,这样的多态性在两个人身上产生了什么影响,就是分子医学研究的范畴了。 上世纪80年代,有这样一个案例:研究发现一个牙买加人(Jamaican)的家族中,大量的“胚胎血红蛋白”在成人中依然存在。对他们的基因DNA编码测序,发现在启动血红蛋白产生的基因DNA编码上,有一个位点的碱基字符是G,而其它正常人的身上,这个位点是C[注释 2]。显然,就是由于这个位点产生的突变,导致胚胎期运行的程序,在成人体中依然开启(见柯林斯编写的“上帝的语言”第5章)。对于这个疾病(“地中海贫血”),虽然有“通过校正致病的突变基因编码”进行治疗的研究,但至今还没有看到成功的案例。 在柯林斯研究团队发表的这个报告上说:DNA编码序列的第“-202”位点上,正常人的DNA编码是’C’,而患者的DNA编码突变为’G’,因此形成了这种类型的“遗传性持续性胎儿血红蛋白综合征”(hereditary persistence of fetal hemo-
globin, HPFH)。报告还说:“测序显示,在总共1500个DNA编码上,仅仅只有这唯一的一个“异常”(SNP)(“The only unique abnormality encountered in a total of 1500 bp is that shown. ”)。1984年能有这样的研究成果,在医学研究上,的确是一个突破。也因此,年轻的柯林斯博士获得了很大的荣誉。 分子人类学不会关注它的医学影响,而是注意到:(1)人类的DNA编码是多么严格,在上万代的繁衍中,依然保持了整体的一致性,否则,人类就会疾病丛生。(2)人类基因的DNA编码是那么高度的一致,在1500个编码上,有1499个位点上的DNA编码相同,仅仅只有一个差别。(3)这样极其一致的编码不可能是随机形成的。 总得来说,SNP学说本身就是建立在DNA编码高度一致性之上,如果人们的基因,每100个DNA编码有几十个码不同,那就不存在SNP的问题了。正因为不同人的同名基因DNA编码差异很小,才会有SNP的研究。那么,不同人的基因DNA编码差异(SNP)到底有多大?这就是一个十分重要的问题。有两个报告给出了参考依据:常染色体的SNP平均是千分之1.2,也就是说:大约平均每800个位点上,有一个位点存在多态性(SNP)(参看本网第6节,1092个人和100个人的DNA基因组报告)。也有资料说,平均200到300个位点上,有一个SNP。在本网附录中,给出的24个基因DNA编码样本,其中19个样本没有多态性(没有SNP)。24个样本的总计19,664个DNA编码中,有14个位点存在多态性(SNP)(
包含突变和缺失),平均每1400个位点有一个SNP。 (3)分子人类学注视的DNA编码 和分子医学不同,分子人类学关注的是全体的DNA编码,既包括基因的DNA编码,也包括那些占97%范围的非基因区的DNA编码。 和分子医学另一个不同的是,分子人类学首先关注的,不是不同人之间DNA编码的差异,而是他们DNA编码序列之间的相同。如果DNA编码平均每800个点有一个点的SNP,那么就应该有799个点的编码相同;即便是在300个位点上有一点不同,也有299个编码点的相同。SNP研究是为了寻求不同人群在DNA编码的差异,另一方面,同样也是SNP反证了人群在DNA编码上的高度一致。 从分子人类学对DNA解码的观念,来看基因DNA编码的多态性(SNP),可以归结出3个结论: 1) SNP反证了人类基因DNA编码的一致,一致的DNA编码说明全世界的人出自唯一的一个源头。 2) 人类基因SNP微小的差别使得全世界人在形体上极其一致,在“非物质遗产信息”上也极其一致。因此,不同族群人们才可以通婚和思想交流。如果人类没有这样基因DNA编码的一致,将会有千奇百怪的人群。 推广到其它生物的基因DNA编码,同样存在基因的SNP。因此,全世界各地的鸡(鸭、牛、羊等动物)才能既有差别,又十分相似。全世界各地小麦(稻米等植物)的形态、成分才那么一致,而不会有长得千奇百怪的品种(参看本网第10节)。 3) 因为人类基因有SNP微小的差别,才使得全世界的每一个人都互不相同,才能分辨出你和我。由于DNA编码数量的巨大,虽然突变差异的比例很小,却由于差异位置组合的不同,在世界的过去、现在和将来,永远不会产生完全相同的两个人。每一个你永远都是独一无二的! 既有一致、又有差别,这是多么奇妙又完备的结合! 人类染色体上的两万多基因,即使有一万多基因是这样的,这里就有一些十分严肃的问题:这样极其一致的DNA编码是怎样形成的?为什么差异这样小?这样小的差异显示了什么?为什么很多基因编码没有多态性? 形成这样一致的编码,有两个选择供思考: (1)全人类来自一个共同的起始个体,随着上万代的繁衍,因为突变产生了DNA编码的差异(千分之0.5); (2)是在人类繁衍过程中,靠突变、“联会”等随机因素带来的演化,形成了这样一致的编码。 我们知道,在人类繁衍过程中,能够使DNA编码改变的因素,有“减数分裂”过程中的“联会”。在“联会”时,父亲和母亲的同号染色体(Homologous chromosomes),会有DNA编码片段的交换;另一个因素是在细胞增殖中, DNA编码序列会发生个别DNA编码的突变。而这两个因素,都是随机发生的。随机发生的因素只会使原有的序列产生差异,而不会令全世界人的DNA编码序列,在不同的繁衍历史中,实现这样高度的一致。因此,读者在上述两个可能中,选择哪一个,应该非常明确了。全世界各族群的人们DNA编码极其一致的事实,毫无疑问地证明了进化(或演化)论仅仅是一个错误的假想。 同时,极其相同、高度一致的基因和非基因DNA编码序列,不但标志着我们身体——“物质的遗传信息”高度的一致;也标志着DNA编码载体上的“非物质的遗传信息”高度一致。全世界人在这两个信息的差别上,仅仅只有千分之一。而全世界人和他们的共同祖先(科学亚当与科学夏娃)的差别,仅仅只有千分之0.5。 最后需要我们去思考的是:为什么常染色体上全部的DNA编码,男女都没有区别?这个问题,我们将在本网导读2中,从编码和数学上来回答。 另外,从本网第10节(DNA编码与解码之物种起源学)的内容中可以看到,上述分子人类学对人类DNA编码的分析,也适合去分析其它动物和一些植物体内的DNA编码。 注释: 1. Judith E. Karp and Samuel Broder, ”Molecular medicine encompasses
the discovery of fundamental molecular components that determine normal
cellular behavior, the dissection of aberrant genetic expression or
interaction, and the modulation or correction of those aberrations for the
purpose of disease prevention and cure.”
New Directions in Molecular Medicine , Office of the Director, National Cancer
Institute, 2.Francis S. Collins,et al. , Gγβ+ Hereditary
persistence of fetal hemoglobin: Cosmid cloning and
identification of a specific mutation 5' to the Gγ
gene,Proc. Natl. Acad. Sci. USA Vol.
81, pp. 4894-4898, August 1984 Genetics |